60-Second Summary
- AI agents fail silently because wrong outputs reach customers before anyone notices. Observability is how you stop that.
- Instrument every agent action with structured traces — capturing model, tokens, latency, and tool calls — so you always know what happened and when.
- Monitor memory across multi-agent systems to catch session drift and context poisoning before they corrupt responses
- Track cost per agent, routing expensive models only to high-stakes tasks and cheaper ones for routine work
- Auto-score every output for hallucinations and policy violations before they reach users
- Tie metrics to real outcomes like tickets resolved and hours saved — leadership buys results, not dashboards
- Trigma doesn't just track what your agents do; they measure whether your agents are worth the investment.
What if your AI agent appears to work perfectly on the outside, but is breaking on the inside? While customer service stays online, agents drift, and you only find out when customers complain or auditors ask.
Unlike traditional release cycles, one of the key operational risks that agents introduce is that they fail quietly and evolve faster.
But when they are talking to your customers or making decisions for your business, you need to monitor where it started, what outcomes it is producing, and whether it is providing correct responses.
That's why implementing observability is crucial to gaining end-to-end visibility into your AI system and understanding why issues occur. This blog covers how you can implement observability in agentic AI workflows, from development to deployment.
Why AI Agent Observability Matters for Enterprises?
AI agent workflows are becoming complex; observability tools are becoming a lifesaver, providing visibility into what the agent is doing by collecting signals such as logs, model outputs, and data flows throughout the lifecycle.
It helps leaders quickly figure out what went wrong and why. With observability, you can trace the root cause, whether it’s a new version of the underlying LLM rolled out without proper testing, outdated data affecting outputs, or a new model introduced without deployment quality checks.
But what if that’s a multi-agent system? Then you need complete visibility into how a group of agents are working, such as
- Which agent handled the request
- Why was a certain decision made
- What tools are used
- How long does each step take
- How much does it cost
- Whether the response was accurate
- Where things went wrong
- Where human intervention was needed
Without observability, AI agents would act like black boxes; you don’t know what they’re doing or whether they’re making mistakes.
With observability, they become trackable, transparent, and manageable.
Example
A support agent processes a refund request. It pulls data from CRM, generates a response, and sends it to the customer. But the CRM had outdated information, so the refund amount was wrong. No error was triggered, and no one noticed.
With observability, the system flags the incorrect input before it reaches the customer.
Core Components of Enterprise AI Agent Observability
Here are a few components of AI agent observability, which are as follows -
1. Tracing Layer
This is the foundation layer where every step an AI agent takes, such as reasoning, tool usage, memory access, and responses, should be tracked as a structured trace.
This uses a hierarchy in which the parent span represents the full user request, the child span represents individual agent actions, and nested spans capture tool, API, or database operations.
Together, this creates a complete execution flow across agents, recording details such as agent name, task ID, prompt version, model used, token usage, latency, tool used, and final output, typically using tools such as Langfuse and Telemetry.
2. Logging Layer
The logging layer ensures that all system activity is recorded in a structured and searchable way. Instead of plain text, AI systems use structured logs to capture input, outputs, tool responses, errors, guardrail triggers, agent decisions, and session metadata.
These logs must be searchable by agent, user, workflow, time, or incident while also meeting enterprise requirements such as JSON formatting, PII masking, retention policies, and audit readiness, often supported by tools such as PostgreSQL and ElasticSearch.
3. Memory, Context, and State Monitoring
In multi-agent systems, memory issues are among the most common failures, and they often go unnoticed because they don’t cause obvious errors. Instead, they quietly affect how agents behave and respond.
This is why it’s important to monitor how memory and context flow through the system. You need to track what information each agent receives, what it stores, what it passes to other agents, what gets cut off, and whether there are any conflicts in stored data.
By monitoring this, you can detect key risks such as -
- Lost context - the agent misses important information needed
- Session drift - the conversation slowly goes off track over time
- Prompt injection via memory - harmful instructions get stored and reused
- Context poisoning - incorrect/misleading data affects future responses
- Duplicate memory states - conflicting or repeated data creates confusion
To manage this, tools such as Redis are used to track and manage session rate efficiently.
4. Cost and Performance Metrics
Every agent uses tokens, and tokens directly increase cost, so it’s important to track usage at every level. Without this, expenses can quickly grow without visibility into where the money is going.
You should monitor key metrics such as how many tokens are used per request, the cost per agent, and per department, how long each step takes, how many requests are handled per minute, the overall workflow, and whether service level agreements are being met.
To optimize costs and performance, the strategy is to use high-end (expensive models) only for complex or critical tasks, while routing simpler or lower-risk tasks to cost-efficient models.
Tools such as LLM Lite help manage this by intelligently routing requests to the most appropriate model.
5. Evaluation and Scoring Pipeline
Every AI agent response should be checked automatically before it reaches the end user. This ensures that poor-quality or risky outputs are caught early rather than going live.
Each output is scored based on key factors such as accuracy, groundedness (whether it’s based on real data), hallucination risk, policy compliance, tone quality, and whether the task was completed correctly.
If a response gets a low score, the system takes action such as sending it for human review, re-running the process, escalating the issue, or switching to a fallback model.
This entire process should run automatically as a pipeline, not manually, so quality control consistently happens and at scale.
6. Security and Governance Layer
Observability is critical in the security and governance layer because it provides visibility into how AI agents behave, make decisions, and access data.
Without it, every action taken by an AI agent should be tracked, including who triggered it, what data was accessed, which tools were used, and what decision was made.
This layer ensures that AI agents operate safely, within rules, and with proper oversight.
It includes controls like role-based access, approval process for prompt changes, audit trails to track options, restrictions on sensitive tools, human approvals for critical decisions, and clear data access policies.
Industries such as healthcare, banking, legal, and insurance require these controls from the very beginning due to strict regulations.
This is what AI agents are: enterprise-ready, not just working systems, but secure, controlled, and compliant ones.
7. Reliability and Incident Management
AI agents need to handle failures safely; they shouldn’t break silently or produce unpredictable results when something goes wrong.
To ensure this, systems should include mechanisms like automatic retries, timeout controls, circuit breakers, fallback models, dead letter queues, and clear incident timelines.
Ultimately, the goal is to see that when things go wrong, the AI agent should handle it gracefully, minimize damage, and stay stable.
How To Implement AI Agent Observability For Enterprise?
Here’s the step-by-step guide on implementing AI Agent Observability in Enterprise -

1. Map The Agent Topology
In this stage, we need to first understand your AI ecosystem. This includes identifying every agent, the tools they use, and all handoff points, data flows, human approval gates, and escalation paths.
A workflow diagram is created to represent the system visually.
If this step is skipped, the observability setup will focus on the wrong documents, and critical failure points will be missed.
2. Instrument Every Agent
Once the system is mapped, the next step is to ensure that every agent action emits telemetry.
Each action should generate logs and traces containing key details such as agent ID, user session ID, task ID, business transaction ID, prompt version, model used, tokens consumed, latency, tool calls, and result status.
For this, open telemetry is used to ensure consistency across different systems and avoid vendor lock-in.
This step creates the data foundation required for observability. If skipped, there will be no data available to analyze, making further monitoring and optimization impossible.
3. Build a Centralized Control Dashboard
A unified operations dashboard must be built to bring everything into one place. This dashboard should include a live agent activity feed, a cost dashboard, trace explorer, session replay, human approval console, incident response, and performance scorecards.
4. Define Alerts by Severity
Alerts must be set up across 4 priority levels.
- P1 ( critical ) includes system outages, workflow deadlocks, and major tool failures
- P2 (High) includes hallucination spikes, latency surges, and escalation surges.
- P3 (medium) includes cost anomalies, quality drops, and queue buildup.
- P4 (Low) includes minor retries and slow secondary tools.
These alerts should be routed to the appropriate teams. Engineering teams handle trace-related events, while business teams focus on cost and quality alerts.
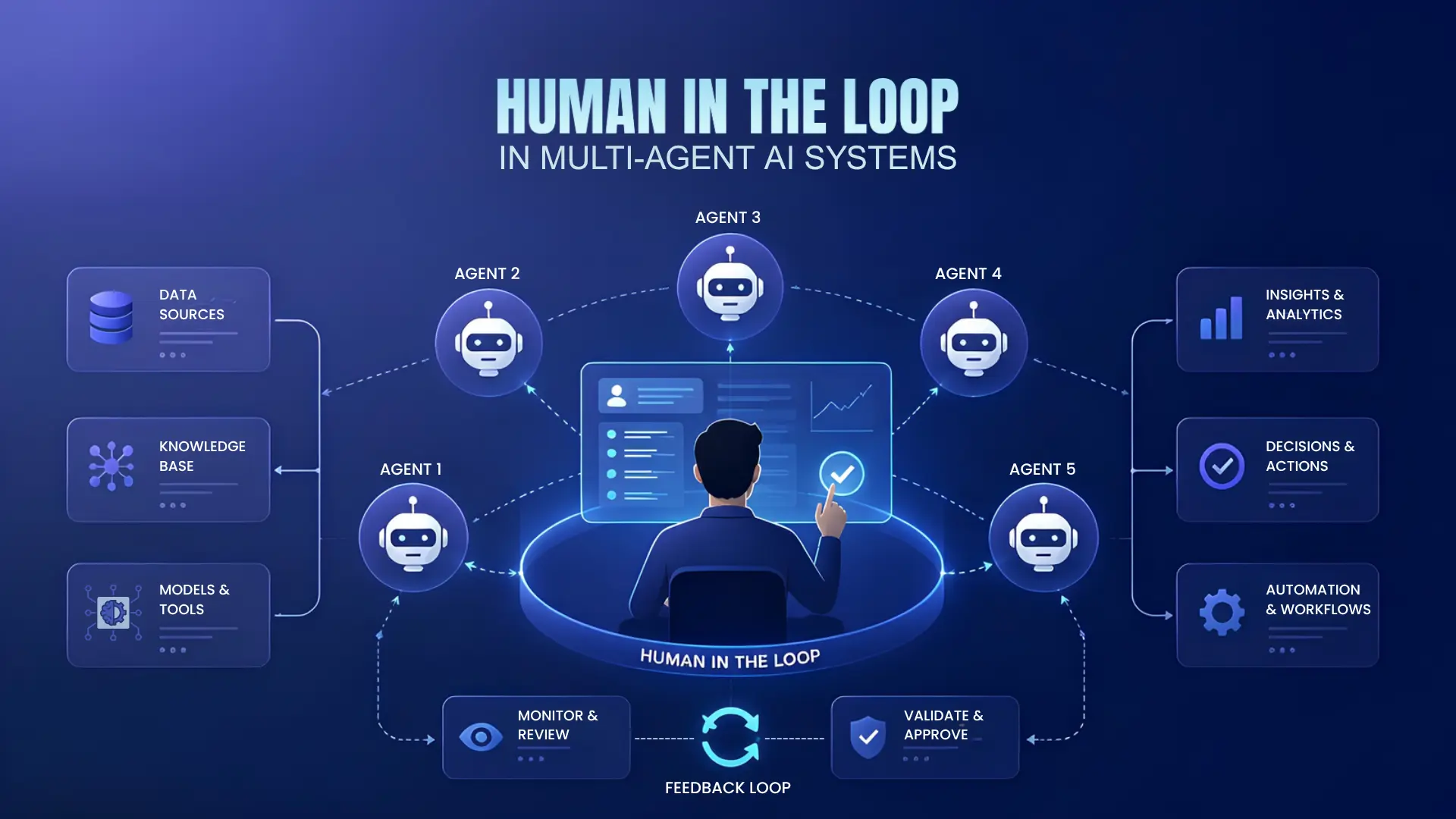
5. Build Human In The Loop Governance
It’s necessary to define which agent actions require human approval before proceeding. This includes actions such as refund approvals, contract generation, customer escalations, financial recommendations, and sensitive communication.
Every human intervention must be tracked, including whether it was approved, rejected, edited, or escalated.
These interactions act as feedback signals that help improve agents' performance over time.
6. Run Continuous Evaluation
Every production AI system requires ongoing automated testing. This includes regression tests for prompt changes, benchmark tests across models, shadow testing for new agents, canary rollouts, and A/B testing for prompt variations.
No prompt or model change should be deployed without running evaluations first.
7. Measure Business Outcomes
Observability is not just about tracking technical data; it’s about connecting it to ROI metrics.
Instead of only measuring the system metrics, the AI agent engineers at Trigma focus on real outcomes, such as
- How many support tickets were resolved?
- How many leads were generated?
- How many tasks were completed?
- How many employee hours were saved, and
- how much revenue is impacted, and
- whether there are improvements in customer satisfaction, etc.
Then, they share these results with leadership teams because they buy outcomes, not data or dashboards.
But skipping this step means you won’t be able to prove the value of AI agents, making it difficult to justify AI investment.
How Trigma Can Help You Make Your AI Agents More Accountable Through Observability Frameworks?
At Trigma, we help you evaluate your existing AI agent landscape to see where agents are deployed, which frameworks power them and what LLMs they use.
We then set up monitoring systems to track metrics, measure the quality of responses, and set alerts with clear escalation rules.
While other observability vendors focus on one thing - what is this agent doing, but we focus on “whether the agent is worth your business or not”. That’s what CTOs and CFOs care about mostly.
Recently, we’ve created an enterprise AI control plane, a platform that manages AI agents like a workforce. How does it work?
It orchestrated multiple AI agents working together, applies guardrails and rules, tracks performance and cost, and enables human oversight through approval workflows.
Best part?
Clearer visibility into AI activity and better decision-making.
Want help in creating an observability framework in your Agentic workflows?
FAQs
1. How long does it take to implement observability in a multi-agent system?
AI observability platforms range from $50/month to over $50,000 annually. The cost generally depends on the type of solution you choose, such as open source or basic tools, SaaS platforms, or enterprise-grade solutions.
Lower-cost tools rely on proxy-based logging, while enterprise platforms follow a usage-based pricing approach, meaning you pay based on how much data your system generates.
2. What is the ROI of implementing AI agent observability?
Implementing AI agent observability gives you a higher ROI, such as faster task completion, reduced manual intervention, lower operational costs, and better customer experience.
3. What should we look for when choosing an AI observability vendor?
Focus on whether the platform gives you real visibility and control, not the data. Key things to look for -
- End-to-end tracking of multi-agent workflows
- Real-time monitoring and evaluation
- Security and governance features
- Scalability for production use
4. Can observability reduce infrastructure costs?
Yes, AI observability helps you identify inefficiencies such as agents calling tools unnecessarily, repeated reasoning steps, overuse of expensive models, and poor prompt design leading to extra token usage.
5. Build vs buy: Should we create our own observability solution?
Building your own observability solution gives you flexibility, but it requires significant time and investment. But buying an observability solution helps you -
- Faster deployment
- Proven capabilities
- Built-in best practices
6. What happens if we don’t implement observability?
Without observability, you lose control over your AI agents. You won’t know -
- Why something failed
- Whether outputs are accurate
- How much value is the system delivering